
Post dial delay should be under seven seconds for most carriers, yet every serious VoIP team should target two seconds or less for competitive customer experience. You can reach that lower target by reducing routing hops, tuning SIP timers, and monitoring every call path continuously with real time dashboards.
Understanding the core concept
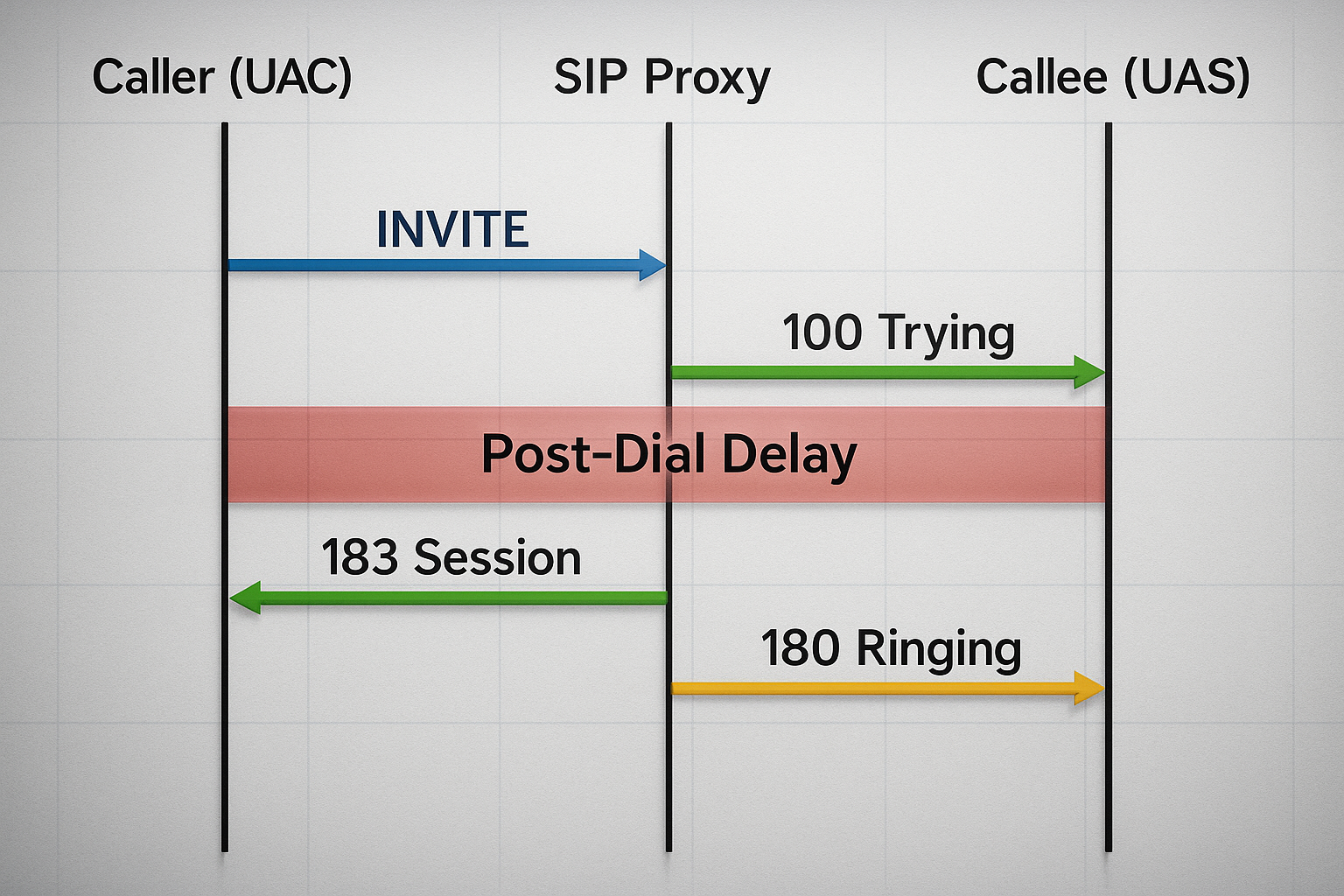
“Post dial delay meaning” is straightforward when explained without protocol jargon: it is the time between the moment the caller presses the final digit and the instant a ringback tone or early media announcement is heard.
In SIP networks the timer starts with the INVITE and stops with the first 18x or 200 OK response, usually 180 Ringing or 183 Session Progress. Because multiple intermediate carriers each add processing milliseconds, the total can silently creep upward. The phrase “pdd post dial delay” appears often in operations tickets, yet it always refers to the same simple measurement.
The industry standard everyone quotes
Most carriers worldwide treat seven seconds or less as the “post dial delay industry standard” threshold; problems below that number rarely trigger trouble tickets. Several widely cited glossaries and Telnyx support notes repeat this benchmark derived from ITU-T recommendations on call setup delay.
However, user perception research shows frustration emerges at five seconds in North America and even earlier for high urgency calls like emergency services. Therefore “acceptable post dial delay” is really context dependent, and best in class providers now advertise sub three second averages to win enterprise contracts.
Hidden factors stretching “post delay time”
- Excessive routing hops add serialization as each intermediary performs number translation and fraud checks.
- Digit collection timeouts in legacy PBX dial plans wait to see if users will enter extra digits.
- TLS handshake latency forces new secure sockets for every fresh call when keep alive is disabled.
- Codec negotiation loops offer long preference lists that bounce back and forth before settling.
- Geographic distance or satellite legs create unavoidable propagation delay, yet smart edge media can trim route miles.
- Database dips for CNAM, LCR, or fraud scoring hold the SIP INVITE while lookups complete.
Each root cause can be isolated with packet captures and timing graphs, letting engineers assign an exact number to every stage.
Measuring “post dial delay time” with confidence
Modern monitoring stacks such as Wireshark, sngrep, Homer, or managed services embed timestamps directly into SIP trace views. Look for the delta between the initial INVITE and the first 180 or 183 message, then store that metric as “post_delay_time” in Prometheus for long term alerting. Set warning alerts above four seconds and critical alerts above seven seconds to align with common carrier expectations. When possible run synthetic probes from multiple regions so you gain visibility into location based variance.
Step by step optimization playbook
1. Remove unnecessary digit collection
Disable overlap dialing unless absolutely required, and shorten T302 timers so the PBX immediately forwards fully collected numbers. This single tweak can shave entire seconds in environments still using default six second waits.
2. Keep SIP and TLS connections warm
Persistent TCP or TLS sessions eliminate certificate handshakes on every call attempt. Many operators cut one to two seconds instantly by turning on session reuse and periodic keep alives.
3. Streamline codec negotiation
Offer only the small subset of codecs actually used in production, ideally one narrowband and one wideband choice. Fewer options mean fewer 200 OK retries and less laboratory style negotiation chatter.
4. Prioritize route quality over lowest cost
Least cost routing looks great on spreadsheets yet often adds transit carriers. Test alternate premium routes where “post dial delay time” drops dramatically, and calculate whether the higher per minute rate is offset by improved answer rates.
5. Parallelize external lookups
If you need CNAM, fraud, or CRM dips, make those requests asynchronously while forwarding the INVITE downstream, rather than blocking the call path. Edge microservices or lambda functions often accomplish this with minimal development work.
6. Leverage early media correctly
Sending comfort announcements or ringback tones through early media does not shorten true PDD, but it masks silence, improving perceived responsiveness. Always pair early media with actual delay reduction for genuine value.
7. Negotiate better SLAs with carriers
Carriers know that “is there a delay in post” questions come when call center metrics fall. Push for contractual clauses that guarantee sub three second averages on major routes and refuse to pay surcharges on underperforming trunks.
8. Automate continuous regression tests
Run hourly synthetic calls across every critical destination, storing PDD data for automated anomaly detection. Tools such as SipFront provide APIs for scheduled testing, ensuring regressions appear in Slack channels long before customers complain.
Each action solves a specific bottleneck and collectively drives measurable improvements visible within days.

Business outcomes of consistently low PDD
Teams that reduce PDD by even two seconds typically witness answer seizure ratio lifts of three to five percentage points, translating directly into more conversations per agent hour and higher closed won revenue. Customer satisfaction scores rise because callers stop experiencing “dead air” anxiety at the start of interactions. Operational costs drop as ticket volumes related to “calls not connecting” decline, freeing support staff for proactive initiatives. Further, marketing campaigns using click to call experience improved attribution accuracy when fewer prospects abandon during call setup.
Frequently asked questions
1. What is a good “acceptable post dial delay” for modern contact centers?
Anything under two seconds delights users, while carriers often consider seven seconds acceptable.
2. Does early media truly fix long PDD issues?
Early media only plays audio sooner; it hides silence but does not remove underlying setup delay, so root cause work remains essential.
3. How does post dial delay influence answer seizure ratio?
Higher delays cause callers to give up earlier, creating direct correlations with lower ASR figures that harm revenue across voice centric businesses.
4. Why does “post delay time” spike during peak traffic?
Congestion along shared transit paths adds buffering and queuing, elongating SIP response times until volume subsides or paths are rerouted. Continuous traffic monitoring helps pinpoint peak hour patterns.
5. Can 5G slicing remove all post dial delay?
Lower radio latency helps but cannot overcome poor routing logic, misconfigured timers, or external database lookups within the signaling path, so optimization best practices still apply.
Conclusion
Post dial delay hides in the seconds before every ringback tone, yet it carries outsized influence on user confidence, operational metrics, and ultimately revenue. Aim lower than the legacy seven second benchmark, chase a two second target, and treat every millisecond as a competitive advantage earned through disciplined engineering and relentless monitoring.
Let superU slash your post dial delay with edge routing and live analytics book a free audit today and hear the difference.
Start for Free – Create Your First Voice Agent in Minutes
