
Short answer: Use SuperU when you want end to end voice calls that launch fast, scale hard, and stay cheap at $0.02/min. ElevenLabs offers a range of voices and has Conversational AI calling, but its per minute pricing and burst rules move your all in costs higher as usage grows.
Snapshot scorecard
| What you care about | SuperU AI | ElevenLabs |
|---|---|---|
| Cost to run calls | $0.02/min pay as you go (simple minute math). | Conversational AI priced $0.10/min (Creator/Pro) and $0.08/min (Business annual); minutes included by plan; per minute beyond that. Burst pricing can double the rate above a call limit and then reject further calls. |
| Latency in live talk | Pluto v1.1 ~200 ms with built in VAD + noise reduction → natural turn taking out of the box. | Flash v2.5 TTS ~75 ms (audio start), with guidance to stream for low latency; end to end depends on your full pipeline/LLM choice. |
| Time to launch | No code, drag and drop; deploy <10 minutes; 100+ integrations. | “Deploy agents in minutes” positioning; minutes are billed by plan and usage. |
| Scalability | Designed for high throughput; docs show 100 concurrent conversations, 100+ languages, and up to 10,000 calls/day today; built to handle “millions of business calls” as you scale. | Scales with your plan and credits; you manage call concurrency within subscription and burst tiers. |
| Adoptability | 24/7 inbound + outbound voice, CRM streaming, website assistants, cold calling, and call center automation. | Strong voice tech; Conversational AI per minute programs with plan based minutes and extras. |
| Support | Human help 24/7 for existing clients and anyone evaluating fit (book a call anytime). | - |
| Who it’s built for | Teams that want calls in production today and predictable minute math. | Teams that value ElevenLabs’ voice models and can budget per minute + burst rules for agent calling. |
Direct answer you can take to a stakeholder
If you need a phone ready voice platform that launches in minutes, feels human on the line, and stays cheap at scale, choose SuperU at $0.02/min. ElevenLabs offers solid Conversational AI, but plan tied minutes, $0.10–$0.08 per minute rates, and burst pricing (double rate beyond call limits) make total cost less predictable in busy periods.
Cost you can verify (and model)
SuperU: flat $0.02 per minute. No plan hoops. No burst penalties.
ElevenLabs: three public signals to price with confidence:
- Help Center table lists minutes included by tier and credit cost per minute; e.g., Creator ≈ $0.12/min, Pro ≈ $0.11/min, Scale ≈ $0.10/min, Business ≈ $0.08/min (annual).
- Pricing start at 10 cents/min… 8 cents/min on annual Business.”
- Agents page: “$0.08 per minute & lower on annual Business.”
Important: Burst pricing can 2× the rate after you exceed a subscription call limit, then reject new calls past a ceiling so your effective minute can spike exactly when volume hits.
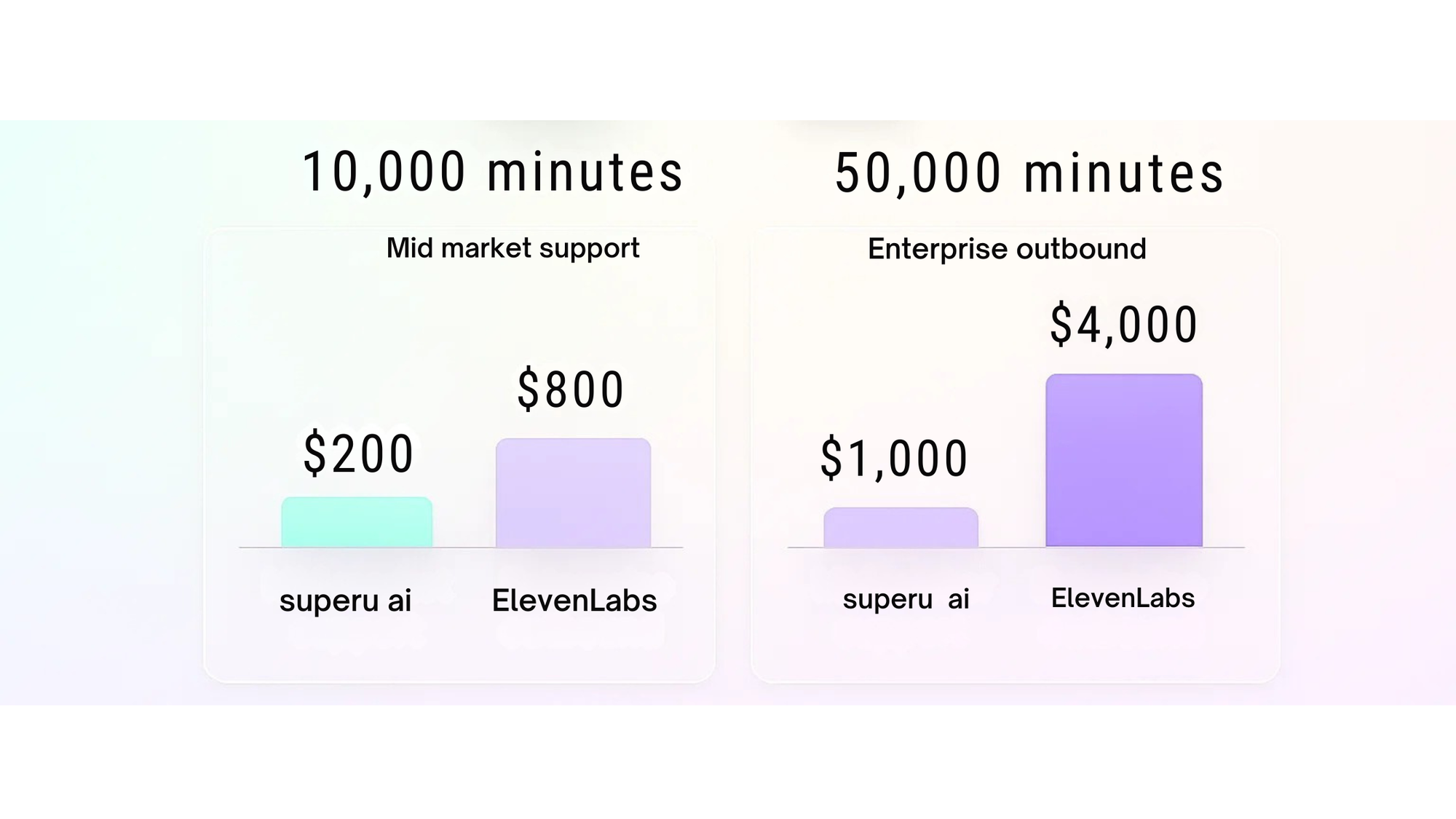
Finance scenarios (talk time only, no SMS/extras)
| Month minutes | SuperU @ $0.02/min | ElevenLabs @ $0.10/min | ElevenLabs @ $0.08/min (Business annual) |
|---|---|---|---|
| 10,000 | $200 | $1,000 | $800 |
| 50,000 | $1,000 | $5,000 | $4,000 |
If you’re near or above a plan’s call threshold, factor double rated burst minutes (e.g., $0.16/min on a $0.08 baseline) for overages until traffic normalizes.
Real time experience (latency, turn taking, clarity)
- SuperU: Pluto v1.1 ships with ~200 ms latency, VAD, and noise reduction so the agent doesn’t clip you, doesn’t babble over customers, and recovers when the line is noisy. You get natural back and forth without tinkering.
- ElevenLabs: Flash v2.5 is a fast TTS model (~75 ms synthesis) and docs recommend streaming to keep latency low; your end to end round trip still depends on LLM choice and the rest of your pipeline.
- LLM variability matters: their own engineering blog notes latency can swing by model and even week to week, so be ready to rotate models to keep response time down.
“From idea to live calls” speed
- SuperU: No code builder, drag and drop flows, and a <10 minute deployment path with 100+ integrations. Click Test Call, tune, and go live. Call data streams to your CRM/dashboard automatically.
- ElevenLabs: you can “create an AI Agent” and “deploy conversational AI,” but you still plan around per minute programs and call limit tiers.
Scalability you can plan around
- SuperU today: Docs show 100 concurrent conversations, 100+ languages, up to 10,000 calls/day, and 24/7 operation for both inbound and outbound.
- Built for bigger: Pluto as “designed to handle millions of business calls” as you scale capacity. If you’re aiming beyond 10k/day, we size clusters with you.
- ElevenLabs: You scale within plan limits; burst tiers apply above subscription call counts. Price impact and call acceptance are governed by that burst model.
What you ship on day one (and day 30)
SuperU gives you the whole calling job out of the gate:
- 24/7 inbound + outbound voice (reception, support, follow-ups, cold campaigns).
- $0.02/min pricing you can explain in one line.
- Pluto v1.1 for ~200 ms turn taking with VAD/NR baked in.
- Python + WebSockets quickstart stream mic ↔ AI ↔ speaker in a few hundred ms.
- CRM ready: stream call data to your dashboard/CRM.
- Clear ROI story: docs frame ~35% more cost effective than traditional call centers when you factor labor and tooling.
ElevenLabs brings top tier voices and a per minute Conversational AI program that you can pilot quickly just remember the plan minutes, $0.10 – $0.08/min baselines, and burst rules when you forecast aggressive growth.
Scenario totals you can show finance (quick hits)
- Outbound reconnection sprint, 10k mins: SuperU $200 vs ElevenLabs $1,000 (or $0.08/min = $800 on Business annual; burst minutes may cost 2×).
- 24/7 support line, 50k mins: SuperU $1,000 vs ElevenLabs $5,000 (or $4,000 on Business annual; watch call limit tiers).
That spread is why teams with real call volume tend to pick SuperU for production voice.
Verdict
If your goal is large scale phone calls with human like pacing, simple minute math, and headroom to scale, choose SuperU at $0.02/min. You’ll launch faster, spend less, and keep turn taking tight thanks to Pluto v1.1 (~200 ms, VAD, NR).
ElevenLabs is a leader in voices and offers agent calling, but its $0.10–$0.08/min structures and burst pricing make budgets wobble during busy weeks.
FAQ
1. How is SuperU priced?
Simple: $0.02 per minute. No plan gymnastics, no burst penalties.
2. How quickly can I go live?
In under 10 minutes. Build your flow, press Test Call, and deploy.
3. What’s the real time experience like?
Pluto v1.1 targets ~200 ms latency and ships with VAD + noise reduction, so calls feel natural even on noisier lines.
4. Can SuperU support my traffic spikes?
Yes. Docs show 100 concurrent conversations and 10k calls/day today, and the stack is designed for millions as you scale with us. We’ll plan capacity with you.
5. Do you offer 24/7 support?
Yes, 24/7 availability for existing clients and for anyone who wants to check how SuperU fits their requirements (book a call and get help fast).
Start for Free – Create Your First Voice Agent in Minutes
